
On The Criteria to be used in Decomposing System into Modules by D.L. Parnas
Paper summary of "On The Criteria to be used in Decomposing System into Modules" by D.L. Parnas, 1972. The importance of encapsulation in a good modularisation.

“If programmers sang hymns, some of the most popular would be hymns in praise of modular programming”
— D. L. Parnas, 1972 [1]
This week i read the paper “On The Criteria to be used in Decomposing Systems into Modules” written by D. L. Parnas in 1972. This article is a summary of the paper. I’ve put in my thoughts and annotations too.
What makes this paper a classic is that although published in early 1970s, the ideas presented in it about modularisation are still relevant in the modern development. One could even extend them in designing distributed systems like microservices. The paper is a very good case for good encapsulation, higher cohesion and lesser couplings wrt modules.
Abstract
“This paper discusses modularisation as a mechanism for improving the flexibility and comprehensibility of a system while allowing the shortening of its development time. The effectiveness of a "modularisation” is dependent upon the criteria used in dividing the system into modules.”
The paper’s major motivation is to explore “how to modularise effectively”. It posits that a good modularisation is not just an assembly of a runnable process, but more than that. It posits that modularisation enables independent development & testing. A good modularisation reduces managerial overhead, increases flexibility and comprehensibility (elaborated later) which in turns reduces development time. It is worth pointing out that Parnas defines “module” as “a work assignment unit rather than a subprogram”.
He adds:
“The modularisations are intended to describe the design decisions which must be made before the work on independent modules can begin.”
Now, this is not to be misinterpreted with big upfront design. But instead, having some directional thinking where your team envisions the software to get structured as. DDD and event-storming fall within this paradigm.
The paper begins by quoting Gauthier[2] that modularisation of code enables independent development and testing with little overhead:
"A well-defined segmentation of the project effort ensures system modularity. Each task forms a separate, distinct program module. At implementation time each module and its inputs and outputs are well-defined, there is no confusion in the intended interface with other system modules. At checkout time the integrity of the module is tested independently; there are few scheduling problems in synchronising the completion of several tasks before checkout can begin. Finally, the system is maintained in modular fashion; system errors and deficiencies can be traced to specific system modules, thus limiting the scope of detailed error searching.”
— Gauthier, et. al. Designing Systems Programs [2]
Parnas, while agreeing with the above, points out that little has been mentioned about the criteria to use in dividing a system into modules. Simply dividing a system into multiple modules doesn’t achieve the expected benefits of a good modularisation. So what are the expected benefits?
Expected Benefits of Good Modularisation
The paper posits that a good modularisation results in following three benefits:
Managerial: “development time could be shortened because separate groups would work on each module with little need for communication (and little regret afterward that there had not been more communication)”; — think about all the communication overheads, dependencies within and between teams etc when there are poor boundaries between different components of a system.
Product Flexibility: “it was hoped that it would be possible to make quite drastic changes or improvements in one module without changing others”; — A whole lot of literature viz. Agile, DevOps, Evolutionary Architecture, Incremental Development, SOLID, DDD etc., talks about this; the ability to increase “changeability” of a software. The greater this ability, the better outcomes for business.
Comprehensibility: “it was hoped that the system could be studied a module at a time with the result that the whole system could be better designed because it was better understood.” — This is really about maintainability of a software and ability to reason with it. The lesser cognitive load a developer has while trying to understand the existing system before s/he can start making changes, the better maintainability of a software is.
So, what should be the criteria of modularisation which sets out to achieve above benefits? This is what is explored in the paper.
At the heart of the paper are two software examples - a KWIC Index Production System and a Markov Algorithm Translator. Parnas uses these two examples and gives different modularisation approaches for them, and then gives reasonings over which modularisation is better. I’ll pick up only the former example for the sake of this summary.
Background on KWIC Index Production System
The KWIC (or Key Word in Context) system was widely employed in libraries to make the text searchable. The system is based on the principle that the title of the document represents its contents. It is believed that the title of the document is one line abstract of the document.
A typical KWIC index system accepts an ordered set of lines, each line is an ordered set of words, and each word is an ordered set of characters. Any line may be "circularly shifted" by repeatedly removing the first word and adding it to the end of the line. The KWIC index system outputs a listing of all circular shifts of all lines in alphabetical order.
Let’s say we have a title of an article/book as “Prevention of diseases of wheat caused by insects”. The first step is to identify a set of keywords to be searchable. Let’s say those are (from the title above): “prevention”, “diseases”, “wheat” and “insects”. The program would accept these keywords along with the title. It interprets the above title then as “Prevention of diseases of wheat caused by insects” (the bolded words are just for illustration purposes. The program may choose alternate ways of recognising the keywords within a given title)
The second step is to circularly shift the sentence so that each significant keyword appears first with the rest of the sentence following it, which the preceding words wrapping at the end (circularly shifting). The outcome of this step would be following list of sentences (note that ‘/’ is used as an identifier of end of original title):
Prevention of diseases of wheat caused by insects
diseases of wheat caused by insects/ Prevention of
wheat caused by insects/ Prevention of diseases of
insects/ Prevention of diseases of wheat caused by
In the third step, the program would take the above list of sentences and arrange them in alphabetical order. So the output of this step would be:
diseases of wheat caused by insects/ Prevention of
insects/ Prevention of diseases of wheat caused by
Prevention of diseases of wheat caused by insects
wheat caused by insects/ Prevention of diseases of
With the above context in mind, let’s look at the two modularisation approaches that the paper illustrates:
Modularisation 1
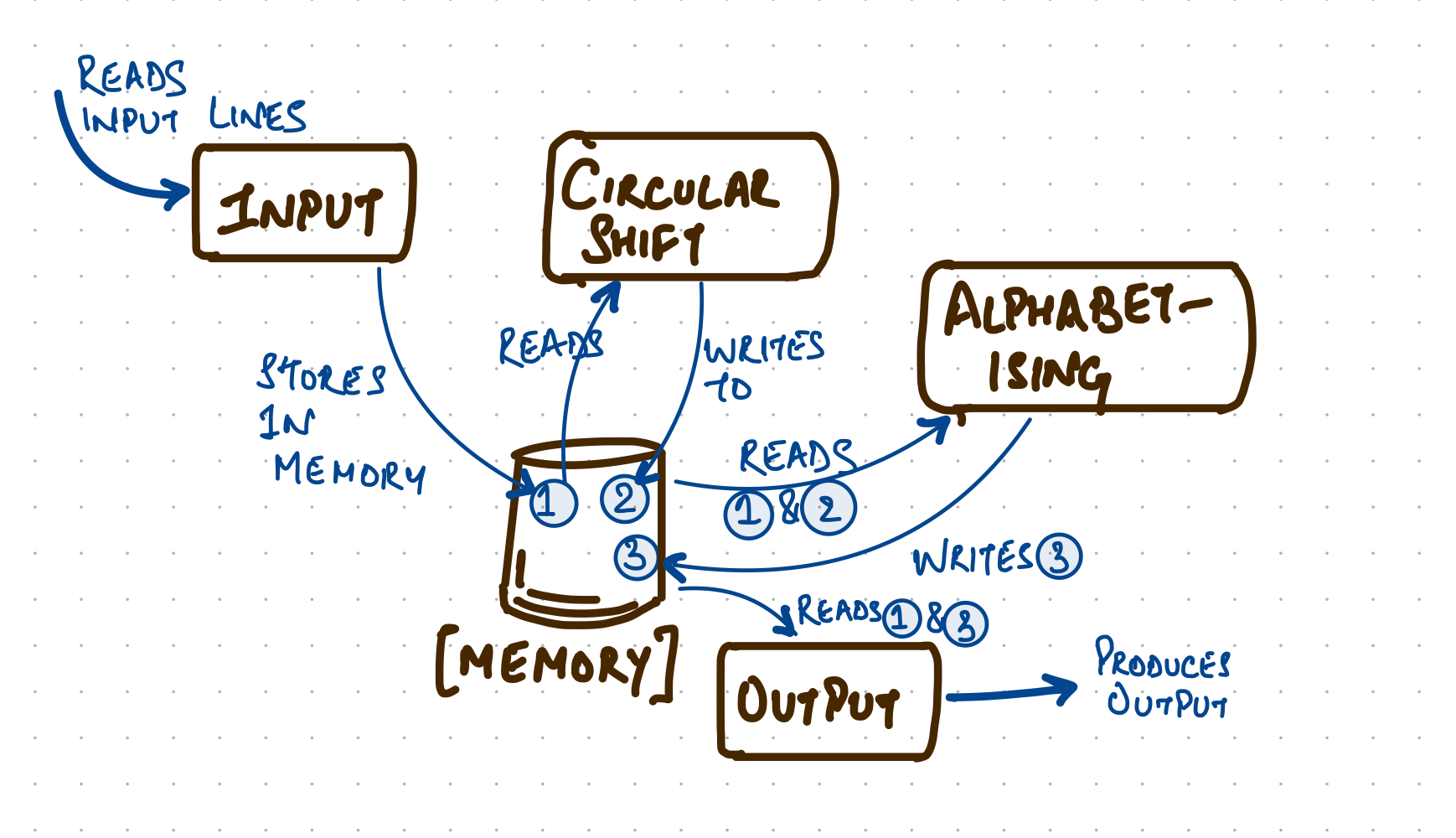
In the first modularisation attempt, following modules are identified:
Input: accepts the input lines from a given medium and stores them in memory
Circular Shift: Called after the input module. Rather than storing all circular shifts in memory, it prepares an index which gives the address of the first character of each circular shift, and the original index of the line in the array made up by module 1. It leaves its output in memory with words in pairs (original line number, starting address)
Alphabetising: This module takes as input the arrays produced by modules 1 and 2. It produces an array in the same format as that produced by module 2. In this case, however, the circular shifts are listed in alphabetical order.
Output: Uses the output produced by modules 1 and 3 and outputs the result.
Master Control: Orchestrates the above modules.
Modularisation 2
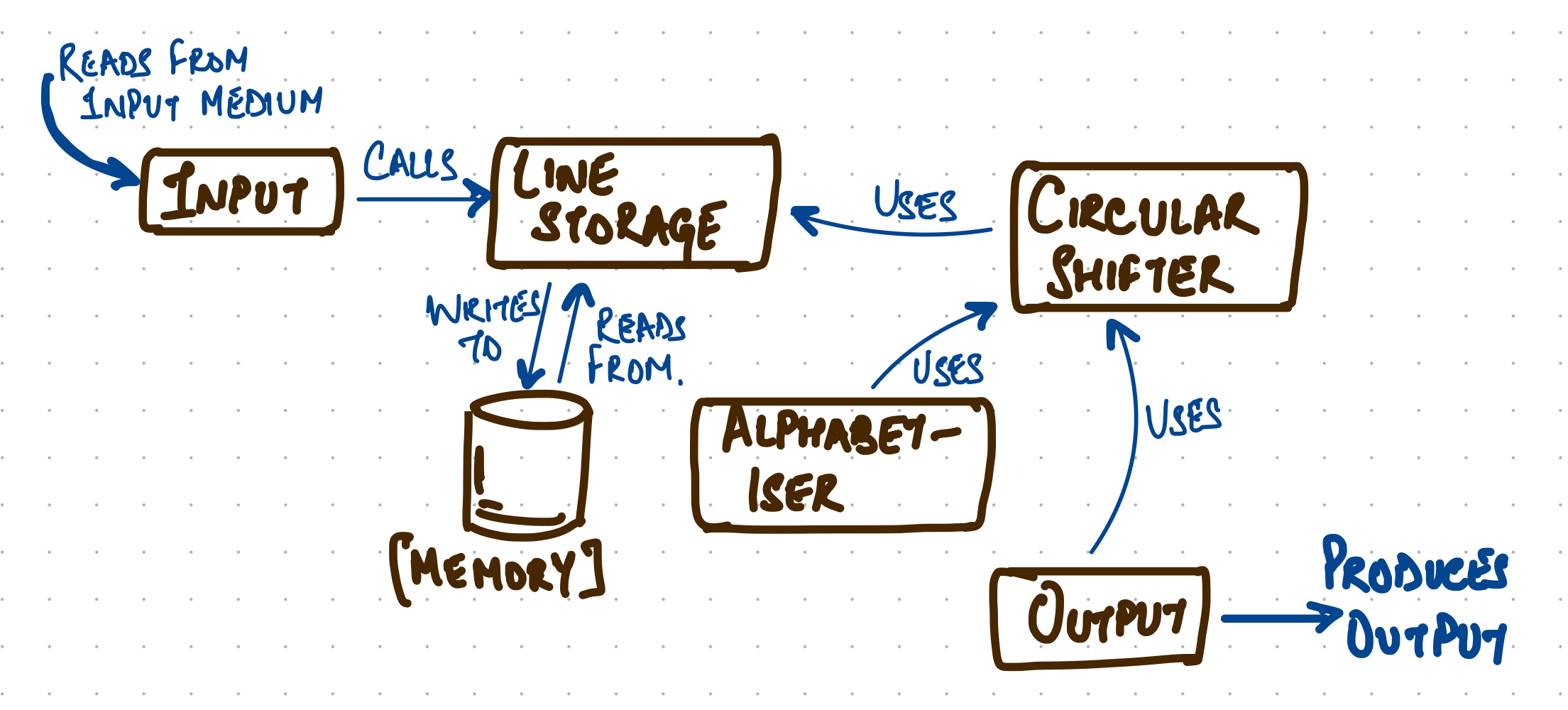
In the second technique, following modules are identified along with their responsibilities:
Line Storage: It contains a number of functions defined on a “line”. For e.g. it contains a function to add a character at a specific position, another function to find the k-th character of a particular word in a given line, another function to set a k-th character of a particular word of a given line, and so on.
Input: Reads the input from input media and calls Line Storage module to store them internally.
Circular Shifter: This module is again defined in terms of functions, similar to module 1. For e.g. it contains function to get characters of a circularly shifted line.
Alphabetiser: It contains primarily two functions: one for setup and the other to get the index of the circular shift which comes i-th in the alphabetical ordering.
Output: This will give the desired printing of set of lines or circular shifts.
Master Control: Similar to its function in modularisation-1
You can begin to see the immediate differences in the two approaches, even though the algorithm of the two programmes remain identical in their “runnable representation”. The biggest differences are that modularisation-2 gets rid of data coupling completely and instead uses functional dependencies between the modules.
Comparison of the Two Modularisations
The paper takes a look at both the modularisations through the lens of the previously stated three benefits of modular programming. Although the two modularisations are almost identical in the way they run, they are significantly different in the way they can be comprehended, maintained and developed.
“I [Parnas] claim that the systems are substantially different even if identical in the runnable representation. This is possible because the runnable representation is used only for running; other representations are used for changing, documenting, understanding, etc. In those other representations the two systems will not be identical.”
Changeability
“There are a number of design decisions which are questionable and likely to change under many circumstances.”
Change in input format. In this case, both the modularisations would need a change. But the change in both is confined only to one Input module.
The decision to have all lines stored in memory. For larger indices it may prove inefficient and impractical to keep all the lines in memory while processing. This change would result in changes in every module of modularisation-1. In case of modularisation-2, the change is still confined to only Line Storage module.
The decision to change the underlying data structure in which the lines are stored. This yet again causes change in all the modules of modularisation-1 but because modularisation-2 abstracts the storage through Line Storage, it is able to confine the change only to one module.
The decision to make an index for circular shifts, rather than storing them as such. This change would be confined within the Circular Shifter module in modularisation-2. In modularisation-1 though, apart from Circular Shift, even the Alphabetiser and Output modules would accrue change because of data coupling.
The theme is clear: better modularisation is able to better confine the changes caused due to future design decisions. This makes modularisation-2 more adaptable to change.
Independent Development
Contrasting between the two modularisations, the paper states:
“In the first modularisation the interfaces between the modules are the fairly complex formats and table organizations described above. These represent design decisions which cannot be taken lightly. The table structure and organisation are essential to the efficiency of the various modules and must be designed carefully. The development of those formats will be a major part of the module development and that part must be a joint effort among the several development groups.“
While the overhead of design decisions is paramount in modularisation-1, modularisation-2 results in lesser development overhead:
“In the second modularisation the interfaces are more abstract, they consist primarily in the function names and the numbers and types of the parameters. These are relatively simple decisions and the independent development of modules should begin much earlier.”
Comprehensibility
In modularisation-1, there is little to no possibility of local reasoning. You cannot understand how Output works without understanding what Circular Shift and Alphabetiser do the underlying storage structure, which in turn can’t be reasoned without taking Input into consideration. This increases the Cognitive load on developers, as they can only understand the system as a whole, not through its different parts.
In modularisation-2 however, because of clear responsibilities of modules, and the fact that they encapsulate the functionalities within themselves respectively, it is relatively easier to reason with and hence improve/refactor and test individual modules without having to comprehend the entire system at once.
The Criteria
Finally, the paper highlights and contrasts the different criteria used in the two modularisation. It states that modularisation-1 is mostly influenced by a “flowchart” of sorts of the programme:
“In the first decomposition the criterion used was make each 'major step' in the processing a module. One might say that to get the first decomposition one makes a flowchart.”
Parnas states that this style of modularisation (modularisation-1) is most common, mainly because that’s how programming is generally taught. My confirmation bias found me agreeing with it completely.
“This is the most common approach to decomposition or modularization. It is an outgrowth of all programmer training which teaches us that we should begin with a rough flowchart and move from there to a detailed implementation.”
He contrasts this with the encapsulation approach that modularisation-2 takes:
“The second decomposition was made using "information hiding" [encapsulation] as a criteria. The modules no longer correspond to steps in the processing. The line storage module, for example, is used in almost every action by the system. Alphabetization may or may not correspond to a phase in the processing according to the method used. Similarly, circular shift might, in some circumstances, not make any table at all but calculate each character as demanded. Every module in the second decomposition is characterised by its knowledge of a design decision which it hides from all others. Its interface or definition was chosen to reveal as little as possible about its inner workings.”
Conclusion
The paper puts forth a strong case of encapsulation as a first class citizen when breaking down the system into modules. It strongly recommends that while it is important to consider the “flow” of the software, it is a poor theme on which the system should be solely be modularised upon.
“We have tried to demonstrate by these examples that it is almost always incorrect to begin the decomposition of a system into modules on the basis of a flowchart.“
It is important to take a Systems Thinking approach and analyse how it affects other teams, think about plausible future enhancements in design with respect to your problem domain, think how work will get hashed out and how to do it with least overheads.
“We propose instead that one begins with a list of difficult design decisions or design decisions which are likely to change. Each module is then designed to hide such a decision from the others. Since, in most cases, design decisions transcend time of execution, modules will not correspond to steps in the processing."
Notes:
[1]: D. L. Parnas. 1972. On the criteria to be used in decomposing systems into modules. Commun. ACM 15, 12 (Dec. 1972), 1053–1058. https://doi.org/10.1145/361598.361623
[2]: Gauthier, Richard and Stephen Pinto. 1970. Designing Systems Programs. Prentice-Hall, Inc.
Hello, and thank you for this clear review — this topic never loses its relevance.
I currently work with data-oriented design, which proposes a different answer to the modularization question: rather than hiding a data structure behind an interface, it suggests separating behavior from data entirely.
This makes me think that there may be more than one valid principle of modularization, and which one applies might depend on the nature of the domain you are working in.
I would be curious to hear your thoughts on how data-oriented design relates to encapsulation as a modularization criterion.