
Monolith vs Microservices : From the team’s perspective

Monolith vs Microservices : From the team’s perspective
Some top considerations while contemplating over Monolith vs Microservices are scalability, independent deployability, increased releasability & maintainability. However, thinking only about application without considering how the choice would affect the team, is like looking at only one side of the coin.

Just as a “good” application which is easier to scale, maintain, release and test enables to serve more end-users (by handling more user requests), a “good” team helps is the force behind success of such applications. While a well structured ecosystem of applications/services is capable of shipping features faster and getting them out to users without having them to wait “too long”, in turn reducing Time to Market, the team is really the hero that makes it happen.
Glossary
Let’s begin by collectively visiting some of the terminologies used in this writeup. If you’re already familiar with them, jump straight to Considerations section.
Modular Monolith:
While referring to a monolith in this article, I’ll be referring to a “single process deployment”, i.e.; a system in which the code is deployed as a single process. There might be multiple instances of this process for scale, resilience etc. But conceptually the entire code is packed and deployed as a single process at a time.
Generally, we think of modularity only from code perspective. However, having modular code is just half the job done. The underlying persistence must also be made modular. So, when you structure your monolith into modules, also have a decomposed DB. Try hard not to have that foreign key reference to another module’s table even if it seems the most sane thing to do.
It might seem an overkill in the beginning to have so many DBs, and it makes sense to have this apprehension. But you can even harness the power of schemas that mostly all the DBs now provide and have separate schemas for different modules.
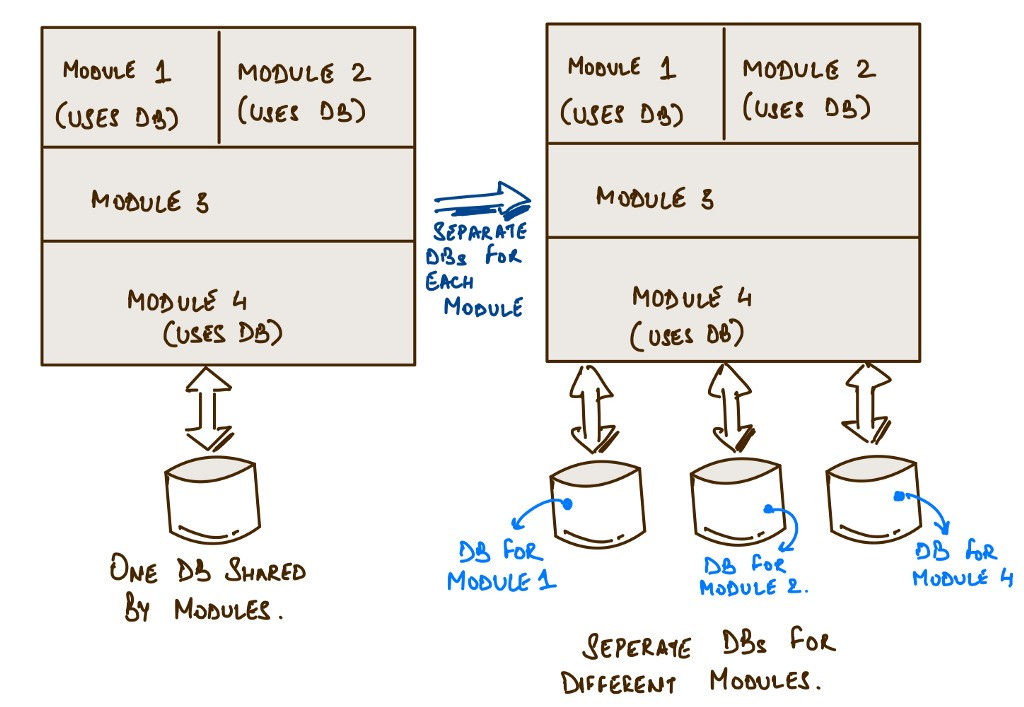
Segregating the code into microservices, still, is relatively easier as compared to separating the data into individual databases (owned by respective microservices) later and dealing with tedious migrations. DB migration is a “hard problem”.
Feature based packaging:
Firstly, if you’re not familiar with software packaging principles, it’s a good place to begin with and understand the underlying concepts behind them. They are as fundamental to writing and structuring code as are SOLID principles.
“Package by layer” is typically what we’re all aware of and most widely used in projects. If say, we’re working on an API service, we’ll try to segregate the packages by layers. So all the code related to routes will go to a route directory, all the code related to services (or adapters) would fall into the infamous services package and then the pattern continues with entities and repositories and so on so forth.
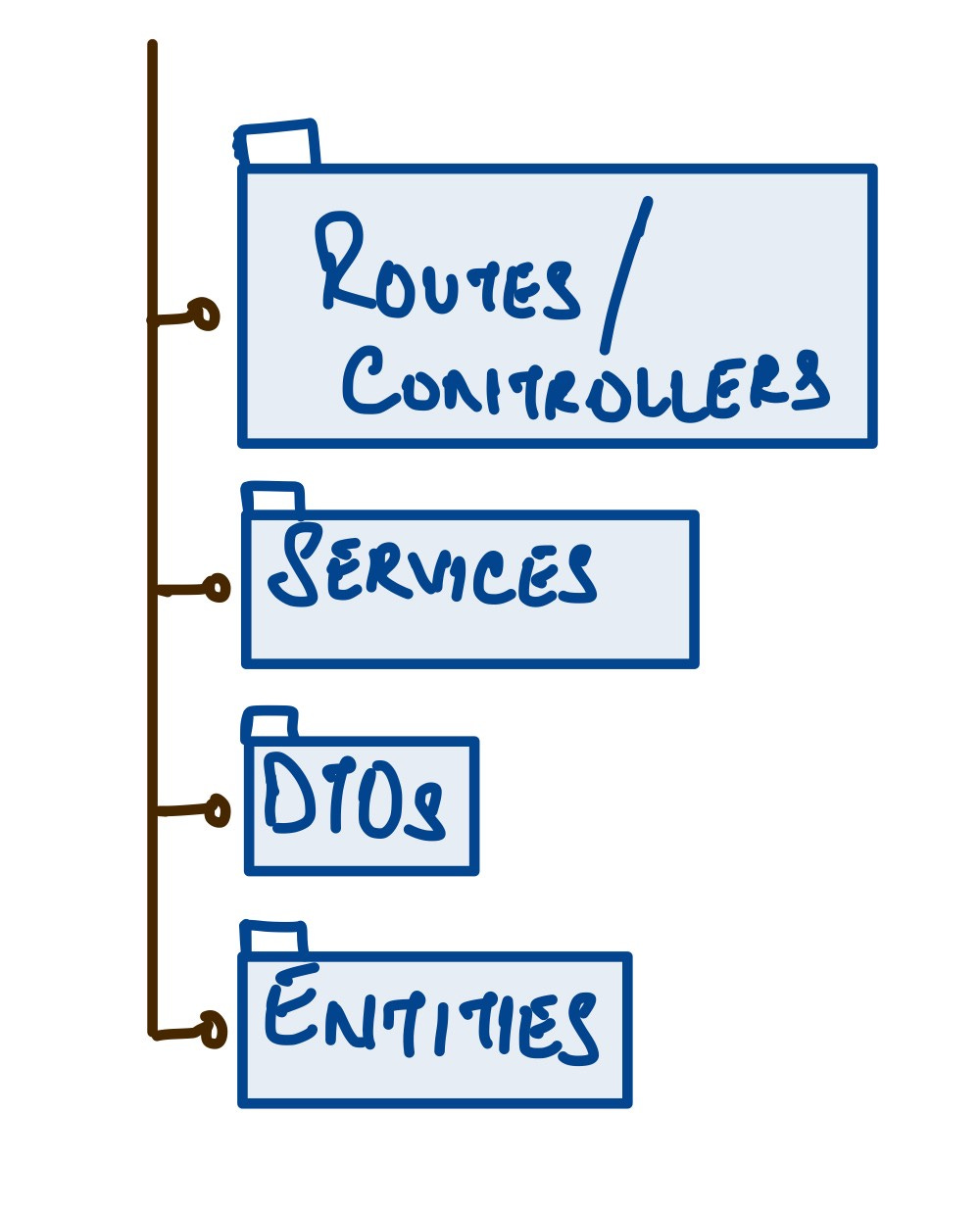
While the most easy to get started with, Package by layer is a maintenance hell, especially as the project grows, more people start contributing and more and more features get developed. Imagine browsing through the entire entities package to find out just the relevant entities that actually require change. Now imagine doing that for all such layers and imagine all the developers and teams doing that, the pain it would cause. In short, discoverability of code is very low.
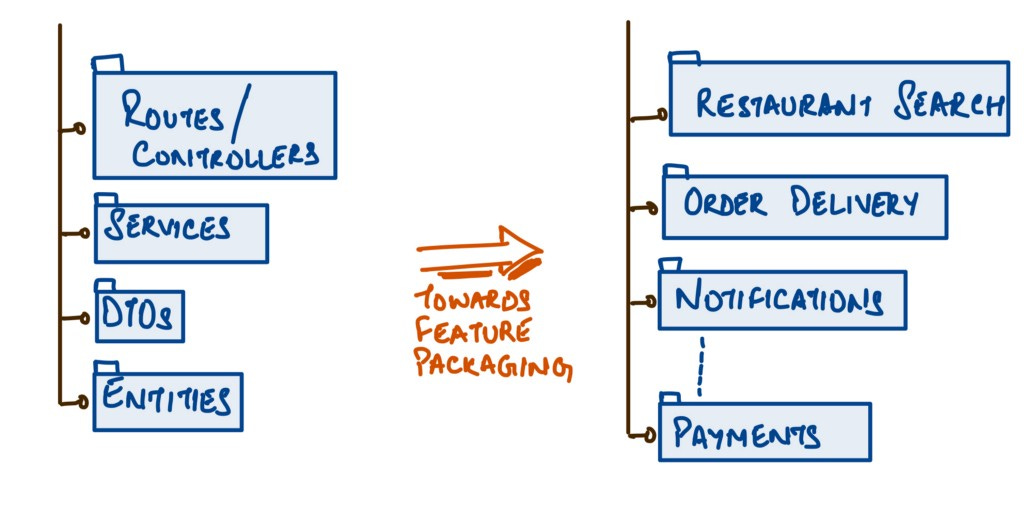
“Package by Feature”, on the other hand, uses packages to reflect the feature set. It’s an attempt to place all items related to a single feature (and only that feature) into a simple directory/package. This leads to packages with high cohesion and modularity, with minimal to no coupling between the packages. You may still have the layered architecture in the feature package to begin with, as shown below, but a good north star is to adopt a more Domain Driven Design based packaging structure. For, e.g. if “Food delivery App” had “Restaurant Search” & “Delivery” as capabilities, each of them would end up as a feature package containing relevant layers/sub-packages within them as shown below:
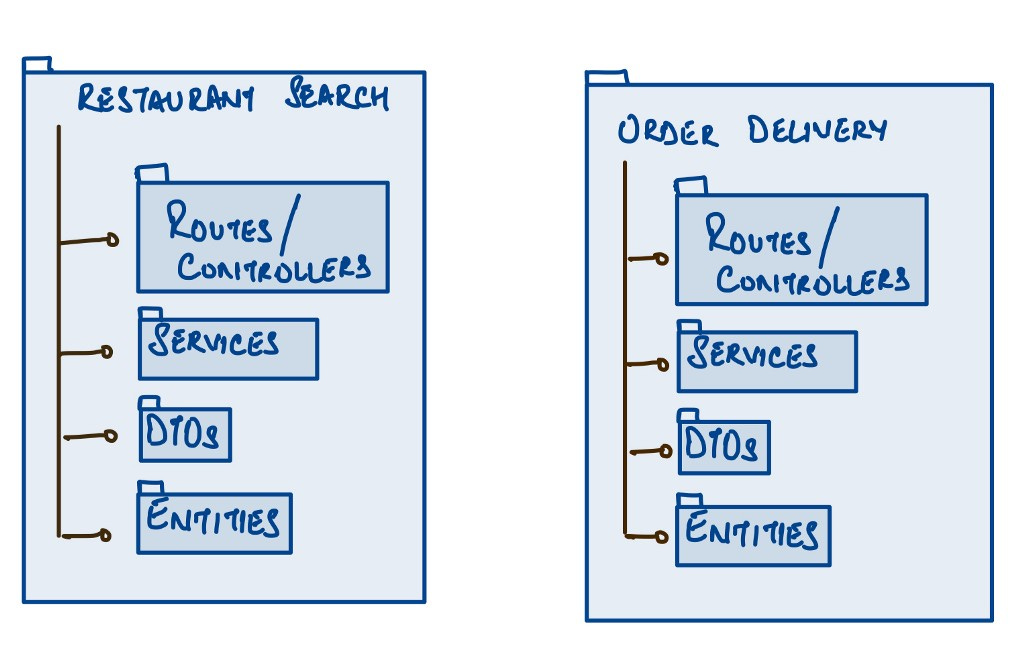
Each feature team can individually grow and maintain their feature packages with minimal conflict and bending their minds to search for the right code file to change.
Cross-Functional teams:
Most conventional organisations have their teams set up in functional silos. A single Marketing team would be responsible for doing all the market evaluations and competitors study for various product lines/features. They’ll relay this to the Product team which is solely responsible to productise it into various features or suite of products. These feature epics would then be passed on Engineering team to execute, through a grandiose planning session. This relaying of information-models from one function to another is so fascinating that I began calling them as Relay-Functional teams, analogous to a relay race, where one runner after finishing his leg, passes the baton to the next one to do his part. In large organisations, the individual functions might comprise of multiple teams within, however, conceptually the information model would still flow from one function (as a whole) to the other.
The most common model that comes to our mind when we think of cross-functional teams is engineering teams. We think of devops. We think of having Devs, architects and QAs as part of the same team and follow the same methodologies and choreograph the various ceremonies together.
That's good. Additionally, we should also strive for getting representatives from other business functions (like Product, Marketing, Sales etc) in the team. Imagine if Marketing person knew exactly what was being worked upon and could do the market-fit analysis alongside. Imagine the Sales person giving feedback ahead of the time what will fly with the customers and what won’t.
It’s difficult to have such a team in the place from the beginning, but it’s completely plausible. Such teams take a bit of sweat, experience and feedback from users to get to the right composition. But the core idea is to keep this at the back of your team’s mind throughout the journey, and not to be “comfortable” with what you have.
Considerations while deciding monolith vs microservices:
Before we dive into the considerations themselves, it’s worth pausing for a moment and understanding what does efficacy of a team really implies. While the ostensible idea of adding more people to the existing teams might seem quite reasonable to help scale the overall efficiency, however there is pretty good evidence in the industry that adding more people doesn’t really mean that the projects are going to be delivered faster. (If you haven’t already, it’s worth reading The Mythical Man-Month which has quintessential essays on this topic.)
Hence, while thinking about scalability, also think about how can existing teams be scaled up with respect to their capabilities and contribution capacity, and not just size.
With the above premise, let’s explore how various considerations play their role in influencing the choice of monolith vs microservices. Moreover, let’s also explore some middle grounds simultaneously.
A team can be scaled effectively on a well structured and modular monolith in a mono-repo codebase too. You don’t explicitly need a multi-repo Microservices based setup to do that. Been there, done that! The key however, is “well structured modular monolith with feature packaging around key sub-domains / business functionalities” (I know, it’s quite a mouthful).
Don’t forget to think about the right team composition. It plays a more crucial role in the overall architecture and structuring of the project than you might have thought of, especially in the longer run. (Oversimplified Conway’s Law)
If essentially you have Relay-Functional teams working in silos, then you’re way better off having a modular monolith backed by a mono-repo. Different code repos maintained by the same team might not be an exciting overhead to have. Some organisations are able to champion this very well. But requires enough maturity in the team. However, the overhead can get overwhelming as the team size increases beyond a threshold (Not quoting a number due to lack of actual research on the threshold. Sometimes wisdom precedes science and statistics)
However, if there are cross-functional teams, i.e. teams composed of Product, Engineering, Marketing etc and each team looks after individual sub-domains or product (sub-products or features too, if I may), then a solution around Microservices, and code split around well identified code repos (e.g. one repo per Microservice is a popular choice) might work wonders for you. Yet again the maturity of the team matters.
When the product is in its nascent stages, the domain is just evolving and very often misinterpreted. Without clear bounded contexts, premature modelling into Microservices might do more harm than benefit. I’m sure you’ve heard of horror stories of teams having to merge services and rethink the boundaries. Not a happy place to be at.
If this is the first time the team is diving into the microservices pool, it’s better to begin with feature teams working on a modular mono-repo codebase. Later split into microservices as the need arises and as the team gains more confidence.
Feature teams give the utmost confidence to Engineering and other business functions alike. It is relatively more comprehensible to think which feature requires more attention than the other, in turn allowing you to focus on particular teams at a time. Also, the approach helps in devising bespoke solutions for respective teams.
You may also go via the library/packages route of taking the modules in the monolith out into separate code bases that yield respective packages. Thereafter, combining them together to deploy the monolith as a single process. The repo separation of packages (suggested segregation based around business capabilities or “bounded-contexts”) helps different teams worry only about code that matters to them. But remember to keep the “packaging principles” in mind else unnecessary dependencies might slow things down instead of helping.
The releasability impedance is also caused by incorrectly identified bounded contexts while using Microservices. These are often termed as “Distributed Monoliths”. It might be easier to recover from a poor structured monolith than poorly structured labyrinth of microservices.
Summary
“It Depends”. Just like most things in software, context is the key. An approach might work beautifully for a team and might not for the other.
When in doubt, try to begin with a monolith. Especially in a startup or when trying to explore the feasibility of a new product. Also stick with monolith if you’re unclear on what problems will Microservice actually solve for you. Use feature based packaging, it will help the team maintain the codebase better as it grows. Put in usage metrics and monitoring. Observe. Usage of the app by the end users is the real truth. See if it makes sense to split features lead by individual cross functional teams yet. Wait for it before going Microservices. You may never require them as well.
If the need occurs, your feature based packaged mono repo can further be decomposed into Microservices much easily as compared to codebases that are structured in a typical 3 tier architectural pattern. Feature packaging helps your team think more about business capabilities (bounded contexts) which are the building blocks of Microservices anyways.
Bonus: Get to know more about Clean Architecture, Hexagonal Architecture and Onion Architecture to take the feature based packaging to the next level by incorporating Domain Driven Design into it.
Monolith vs Microservices : From the team’s perspective was originally published in Geek Culture on Medium, where people are continuing the conversation by highlighting and responding to this story.