
Spec-Driven Development is Missing Its Spec
What the LLM adds when it rewrites its own failing prompts — and what that implies for specs in Spec-Driven Development.

A Dec 2025 ThoughtWorks blog post calls spec-driven development one of the most important new engineering practices to emerge in 2025. The post is generous in laying out what the practice is, how it relates to behaviour-driven development, what tools support it, where it fits in the broader shift toward AI-assisted coding.
It further calls out “there’s not yet a systematic way to evaluate specs as we do with evals.”
So the practice has arrived. The test for the practice has not. We have spec-driven development, and we do not know — in any disciplined sense — when a spec is sufficient.
When a new practice catches on (like SDD), people start using it. The fact that they keep using it gets treated as evidence that it works — even though there’s no actual rubric to evaluate whether what they’re doing is good. Adoption becomes self-validating: “I use this practice, my projects mostly turn out OK, so the practice must be sound.” That’s circular reasoning. The very act of reaching for the practice (adoption) becomes the proof (evidence) that the practice is correct.
Recent empirical work begins to fill that gap.
What the model itself reaches for
In Jan 2026, Midolo et al. published “Guidelines to Prompt Large Language Models for Code Generation: An Empirical Characterization”. The methodology is interesting. They set up an automated, test-driven loop: when a benchmark task’s tests failed, the LLM was given its failing prompt and the test errors and asked to refine the prompt until the regenerated code passed. Across 627 such successful refinements over 4 LLMs (GPT-4o mini, Llama 3.3, Qwen2.5, and DeepSeek Coder V2) — the authors catalogued what kinds of additions the LLM(s) reached for when fixing its own prompt, and how often each appeared.
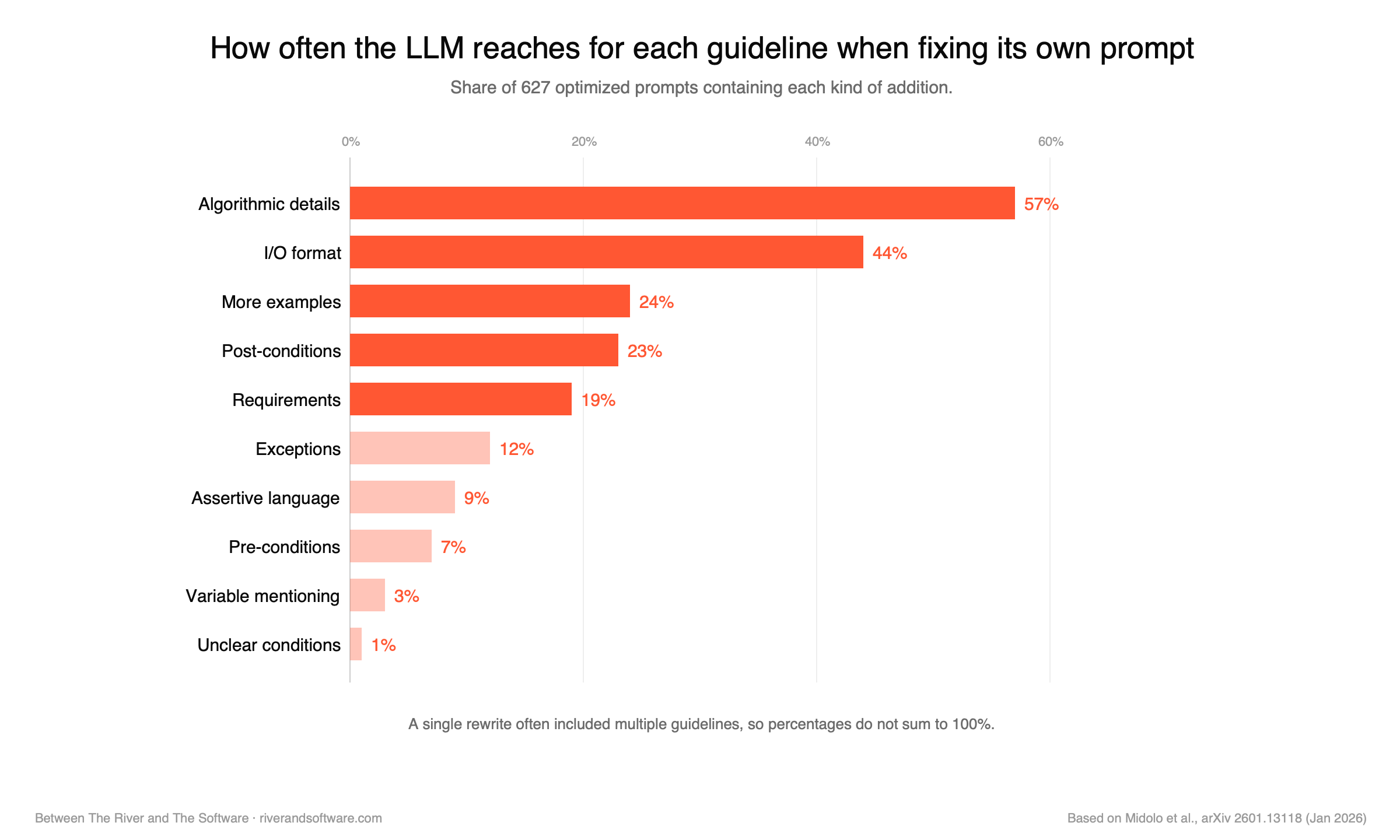
The chart below shows the machine-driven numbers — how often the LLM itself reached for each pattern when given a chance to fix its own prompt.
A separate survey of 50 practitioners asked how often each pattern showed up in their own workflow (when they had to update the prompts themselves). The two datasets broadly agree.
For a complete picture, here is what each guideline actually specifies:

Some examples of prompt changes that the LLMs applied themselves:
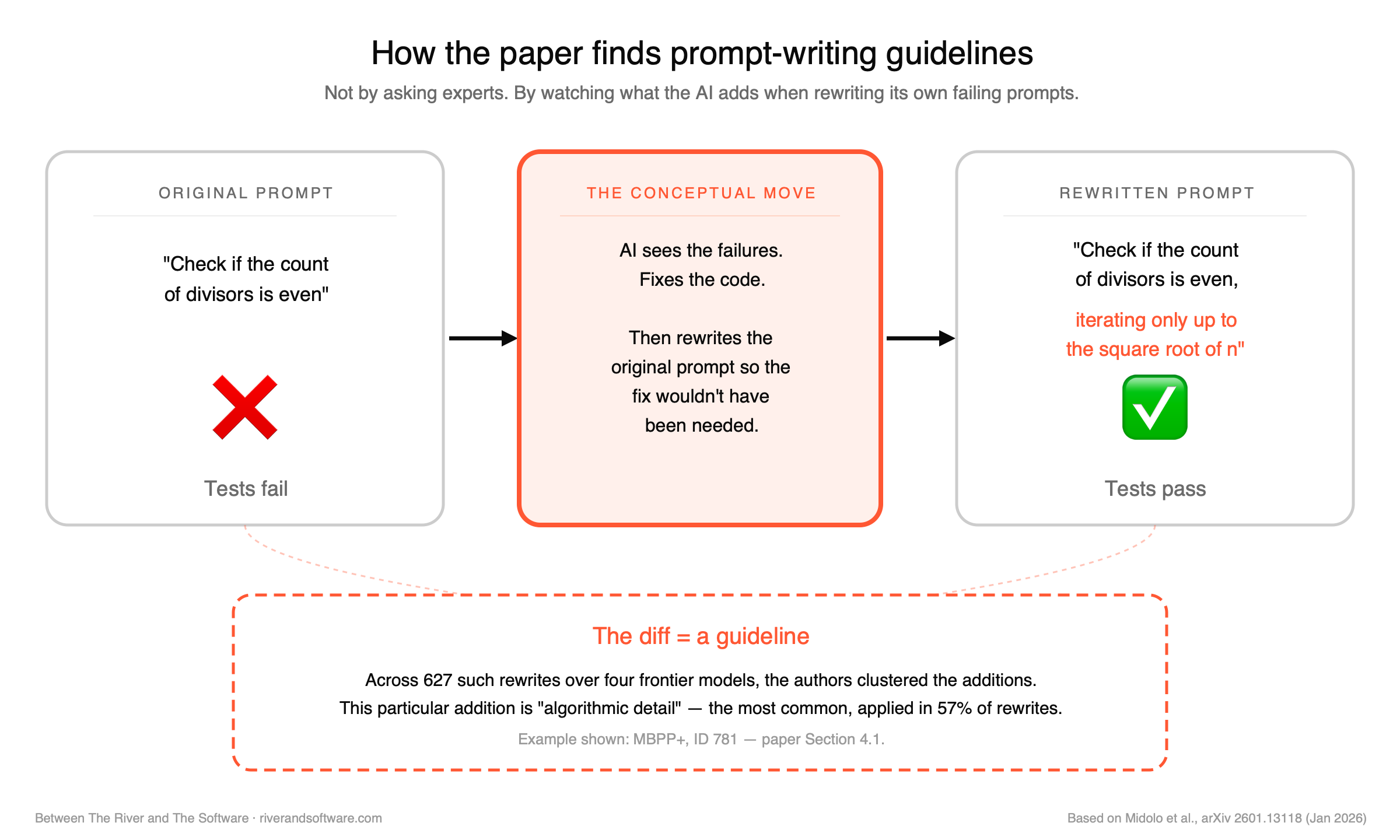
One small Python task (MBPP+, ID 781) asked the model to check whether the count of divisors of a number is even. The original prompt was minimal; the model’s tests failed. Its self-edit added a single sentence: “The function should efficiently count divisors by iterating only up to the square root of n.” That sentence falls under algorithmic detail — the 57% bucket. The model didn’t add an example. It added a piece of the algorithm.
In another task (MBPP+, ID 99) — convert a decimal number to its binary format — the original prompt was silent on negative inputs. The self-edit added: “For negative integers, the binary representation should be prefixed with a ‘-’ sign.”That’s a post-condition — the 23% bucket — but notice what it does. It forecloses a class of silent failure that the original prompt would have allowed the model to drift into.
The ranking reorders the conventional prompt-engineering hierarchy. Most guides — the ones that show up when a new engineer searches how to prompt for code — put few-shot examples at the centre. Examples are concrete, demonstrable, easy to teach. The data says that when the model fixes its own failing prompts, it reaches for examples roughly one time in four. It reaches for structure and contract nearly twice as often.
That’s a result worth pausing on. The dominant moves are about how to think through the problem (algorithmic detail) and what the inputs and outputs look like (I/O format) — not about adding more examples. The prompt isn’t getting more concrete examples; it’s getting a more concrete shape.
A spec, observationally defined
Here is where the paper meets SDD.
The ThoughtWorks post describes a spec as something that “should explicitly define the external behavior of the target software — things like input/output mappings, preconditions/postconditions, invariants, constraints, interface types, integration contracts and sequential logic/state machines.” That’s a long list, and arguably the right target. Personally, whether I draft it myself or have an LLM produce it and then proofread as the human in the loop, it becomes a bit daunting. The honest (and realistic) practitioner question is: which of those elements do most of the work, most of the times?
The ranking gives the beginning of an answer. Five elements appear in more than 15% of LLM self-rewrites — algorithmic detail (57%), I/O format (44%), more examples (24%), post-conditions (23%), and requirements (19%). Together they account for the lion’s share of the observed additions; the remaining five guidelines drop sharply into single-digit territory.
Four of these five map onto that list cleanly: algorithmic detail to sequential logic / state machines, I/O format to input/output mappings, post-conditions to preconditions/postconditions, and requirements to constraints. Concrete examples is the outlier — it sits outside the “external behavior” framing but earns its place empirically through BDD and test-driven traditions.
If you specify those five, you are operating in the high-leverage zone. The other five guidelines — exceptions, assertive language, pre-conditions, variable mentioning, unclear conditions — are second-order moves, useful when the high-leverage moves have already been made.
The convergence within the paper is itself notable. The headline percentages come from automated refinement — what the model adds when fixing its own failing prompt. The same paper’s separate survey of 50 practitioners reports a similar shape — I/O format and pre/post-conditions ranked as most-often used in their own workflows, “by example” approaches less so. Two independent measurements, one paper, pointing at the same elements as the high-leverage moves.
The caveat the paper can’t tell us
My first instinct with a benchmark paper like this one is to ask how much of what it finds survives when the codebase has its own idioms.
The paper studies open-source benchmark tasks — HumanEval, ParEval-style coding problems. These are clean: well-bounded, generic, mostly free of domain context. The kind of tasks an LLM has seen many close cousins of during training.
Enterprise work is messier. There is tribal knowledge in the codebase. There are compliance constraints, regulatory invariants, naming conventions that mean something specific to your team. There is the codebase’s own idiom, which an outside model has no way to infer.
A separate paper from February 2025 by Qibang Liu et al., on prompt length in domain-specific tasks, finds that the relationship between specificity and output quality is more linear when the task is domain-specific. Generic tasks plateau quickly; domain-specific ones keep benefitting from more context. This suggests the spec guidelines weightage is a starting point, not a universal law. For tasks that live in domain — financial calculations, healthcare data, compliance-constrained logic — the ranking probably shifts. Domain context climbs.
The honest version of the heuristic, then, has two layers. For generic work, the high-leverage moves are the five just listed: algorithmic shape, I/O contract, examples, post-conditions, and requirements. For domain-specific work, you also need to carry the domain — the rules, idioms, and invariants the model cannot reach by training alone. That layer doesn’t appear in the Midolo et al. taxonomy at all; it’s an enterprise-context dimension the benchmarks don’t surface. But it becomes necessary, not optional, when the task crosses into your specific world.
Where this leaves us
Reading this as a practitioner, the gap isn’t closed. The fundamental question — when is a spec sufficient? — still doesn’t have a systematic answer. We’re still in the territory of craft sensibility.
But there is something nearer to it now than there was a few months ago. Not a rubric, but a heuristic. Five questions a practitioner can ask of a draft spec before deciding whether to run it:
Have I specified the algorithmic shape — how to think through this?
Have I specified the I/O contract — what goes in, what comes out, in what form?
Have I given concrete examples — at least one usage case covering edge conditions?
Have I specified post-conditions — what must be true after execution?
Have I named the requirements — which packages, libraries, or external tools are needed?
If all five are yes, the spec is past the empirical high-leverage zone. The next move is to run the prompt and see what comes back, not to add another paragraph.
That is a small thing. It does not close the gap. But it is the first place I have seen the gap addressed with evidence rather than craft intuition. The practice came before the test; the test, when it arrives, will probably be built from observations like these.
The wider question is whether spec-driven development settles into a discipline that has its own test — the way test-driven development eventually did — or whether it remains a craft we keep doing without ever being able to teach it as a discipline. That answer is some way off. What such a test would measure, though, we are starting to see.
Sources
Liu Shangqi, Spec-driven development: Unpacking one of 2025’s key new AI-assisted engineering practices(ThoughtWorks, December 2025)
Midolo et al., Guidelines to Prompt Large Language Models for Code Generation: An Empirical Characterization, arXiv 2601.13118 (January 2026).
Replication package on Zenodo — for tracing specific task IDs (e.g., MBPP+ ID 781).
Qibang Liu et al., Effects of Prompt Length on Domain-specific Tasks for Large Language Models, arXiv 2502.14255 (February 2025)
arXiv 2502.14255 - Effects of Prompt Length on Domain-specific Tasks for LLMs
Datasets referenced: MBPP+, BigCodeBench, HumanEval+.
Further reading
Simon Willison, How I use LLMs to help me write code (March 2025) — a practitioner’s account of his daily LLM-coding workflow, including the function-signature-plus-plain-English-description pattern that converges with the paper’s empirical ranking. Useful adjacent reading.