
The importance of having slack in your plans.
The importance of having slack in your planning. Many bad takes on Prime Video's move to monolith from microservices. Cryptography, brief history and basics.

Hope you are having great days and are off to a great start this week. 🍀
This is a fortnightly newsletter in which I share interesting articles, talks, quotes from literature, comic strips 😊 and many such things that I stumbled upon.
Let’s jump straight in.
Three things this fortnight:
The importance of having slack in your plans
Many bad takes on Prime Video’s move to monolith from microservices
Cryptography: History and Basics
As always some relevant links and recommended reads are present in the notes section at the bottom.
But before all, my favourite comic this fortnight. Courtesy @vincentdnl

The importance of having slack in your plans
Teams often get accustomed to their iteration plannings. So much so that they like to optimise for every bit of capacity that they have. If the team’s velocity is 15 stories points on average, it will definitely load up 15 points. At times it would throw in another 3-5 points as a stretched effort, a concept which is as antithetical to flow as possible.
“A plant [system] in which everyone is working all the time is very inefficient”
Although setup as a fiction about a manufacturing plant, the book explains Theory of Constraints better than most others. I particularly like the above quote because it highlights the importance of thinking in systems, as a whole.
Optimising for individuals != Optimising the system
It is intuitive to think that if we optimise for individual resources, the system as a whole will be efficient. If we pull in as much stories as much as we have capacity in this sprint, surely we are efficient, isn’t it? Well, not quite. We’re considering capacity as a sole measure. We’re optimising for one (local) measure.
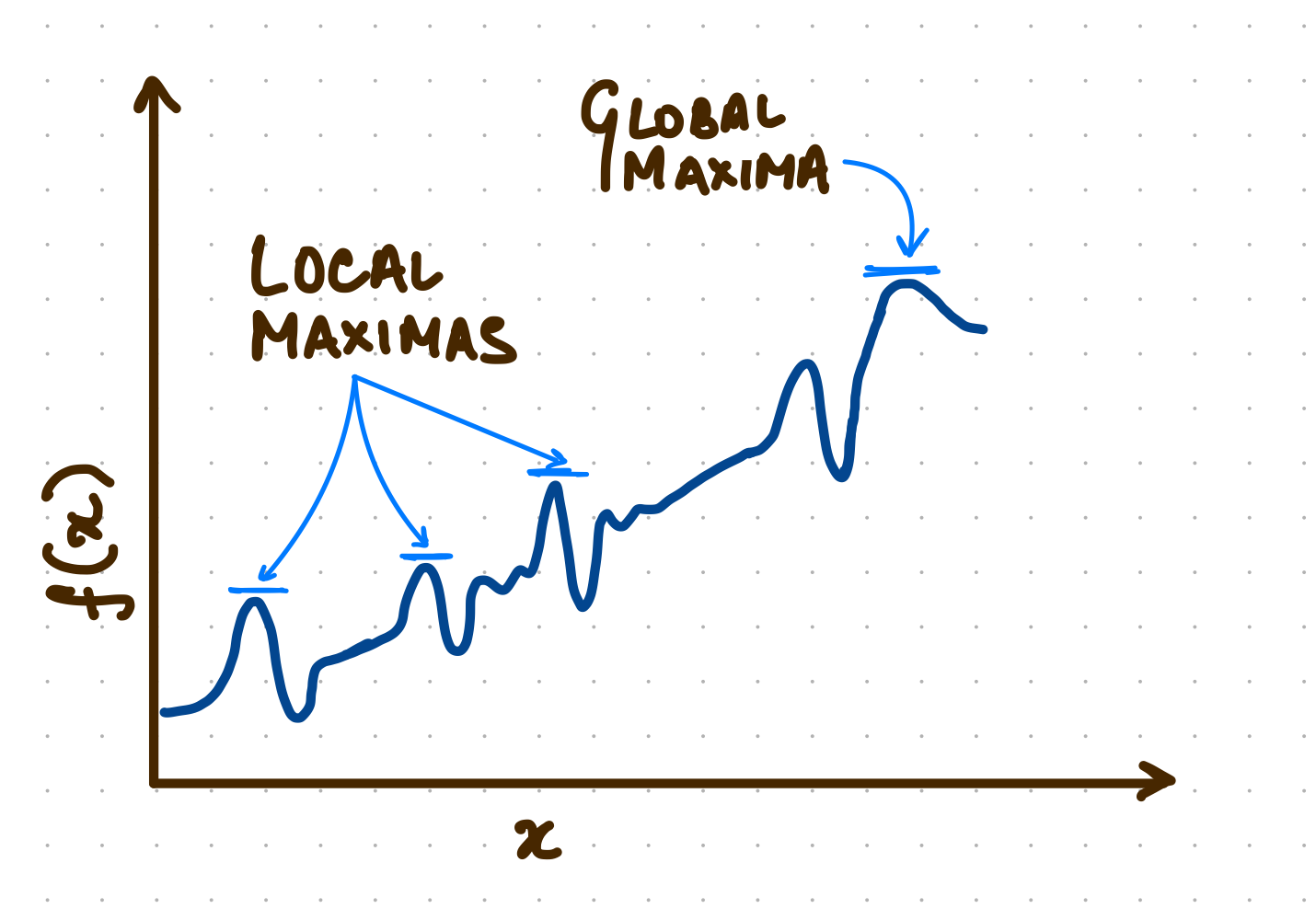
In reality local optimisation doesn’t always lead to optimisation at a global level. As shown in the above pseudo-graph, optimisations done for local or neighbouring problems might result in improvement of the local, a part of the whole system. It doesn’t necessarily lead to the overall optimisation that the system is capable of achieving. When we optimise only for capacity, other BAU tasks which demand capacity of the team take a hit.
A software team has many more responsibilities than just writing new code for that prospect shiny feature which is hypothesised to earn that extra revenue. It has to look after the cruft in codebase, optimise the load balancing of resources, monitor the deployments and respond appropriately to any unavailabilities of the services, automate that manual task which takes forever and a lot of cognitive load to execute, as so on. Many of these tasks are unpredictable and yet of quite grave importance. How do you plan for these unpredictabilities? — By adding slack to your plan!
In his article Slack, Martin Fowler talks about how you can introduce slack in your plan:
“A good way to introduce slack into planning is to use it to cope with the inherent uncertainty of planning. A team that averages 20 stories per iteration won't complete exactly that number every iteration. Instead we'll see a range: say from 15 to 22. In this situation the team can plan at their lowest consistent number (15) and treat the additional time as slack.“
— Martin Fowler
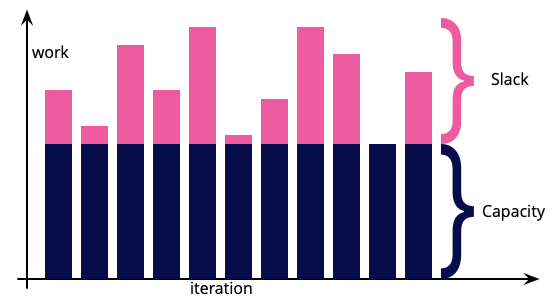
Key takeaways on how to utilise the slack time:
The most obvious thing to do is to tackle additional stories. If the team is done with planned stories, it is good to pull in more work and get more done on an as-possible basis.
Respond to urgent requests. You may choose to have a dedicated “developer on support” person on rota basis. While a dedicated person attends to urgent requests (from end-user, a dependent team, an external vendor) it lets others concentrate on the feature.
Pair on a story and get it to done. Experiment pairing if you have a pull-request based workflow. See if pairing made it any better. At times your QA team might be overwhelmed with the number of stories to be tested, try giving a hand.
Automate that mundane manual tasks which takes a lot of steps to remember, but is mostly repeatable.
Explore how can the builds be made faster and more reliable. Maybe the test setup of your functional tests is flaky. Maybe the assertions themselves are flaky. Maybe there are some tests which should be there but aren’t.
Revisit some of the hurdles which are impeding developer productivity, try to solve them.
Pen down that last important architecture decision that the team took but couldn’t get time to document it.
Improve upon your API document and write down contract tests which have been pending since that new team started consuming your services.
Update the dependencies. Make sure no vulnerabilities are present. Better yet invest time in automating the security within your build pipelines.
The above are just some of the examples; you may have others depending on your context. But the key thing to remember is without having slack, these activities can’t be picked up. While some are BAU activities, some cause impediments and others slow down the throughput of the team over time. It is important to prioritise and revisit.
Many bad takes on Prime Video’s move to monolith from microservices
Recently, Amazon Prime Video’s team published Scaling up the Prime Video audio/video monitoring service and reducing costs by 90% and the internet went wild with their takes on it. Quite a lot of them, quite bad!
One of the good ones I liked is by Adrian Cockraft.
“The Prime Video team had followed a path I call Serverless First, where the first try at building something is put together with Step Functions and Lambda calls. They state in the blog that this was quick to build, which is the point. When you are exploring how to construct something, building a prototype in a few days or weeks is a good approach.
The problem is that they called this refactoring a microservice to monolith transition, when it’s clearly a microservice refactoring step and is exactly what I recommend people do in my talks about Serverless First”
— Source
His take on why microservices are earning a bad rep:
“In contrast to commentary along the lines that Amazon got it wrong, the team followed what I consider to be the best practice. The result isn’t a monolith, but there seems to be a popular trigger meme nowadays about microservices being over-sold, and a return to monoliths. There is some truth to that, as I do think microservices were over sold as the answer to everything, and I think this may have arisen from vendors who wanted to sell Kubernetes with a simple marketing message that enterprises needed to modernize by using Kubernetes to do cloud native microservices for everything.”
— Source
Brief Concept and History of Cryptography
Cybersecurity is a vast and burgeoning field. One of the tenets of this area is privacy. Privacy is all about algorithms and best practices to prevent unauthorised users’ from accessing the data that doesn’t belong to them. The article Cryptography: Brief Concept and History by Ashok Hegde is a recommended read.
That’s a wrap!
Thank you for reading and being part of the community. If you’d like to suggest topics to cover or if you’d like to write for us, do tell us at newsletter@partnest.io.
Have good days! 🍀